随笔 - Jetson 配置 & Jetson 集群.md
友人赠送了一台 NVIDIA® Jetson Nano™ Developer Kit (4GB) 和一台 NVIDIA® Jetson Xavier™ NX,简单做下折腾记录
到手准备
首先是电源的准备,Nano 的基板左侧有一个 5V DC 输入 右侧有一个 MicroUSB (看 PCB 上的预留焊盘应该也可以改成 TypeC) 两者均可供电,DC 输入通过 DC 口边上的 DC EN 跳线实现(有人插上 USB 没拔掉跳线半天没亮灯还以为烧了我不说是谁),USB 口可以使用树莓派的 5V 4A 电源,可以开启满血 20W 模式。
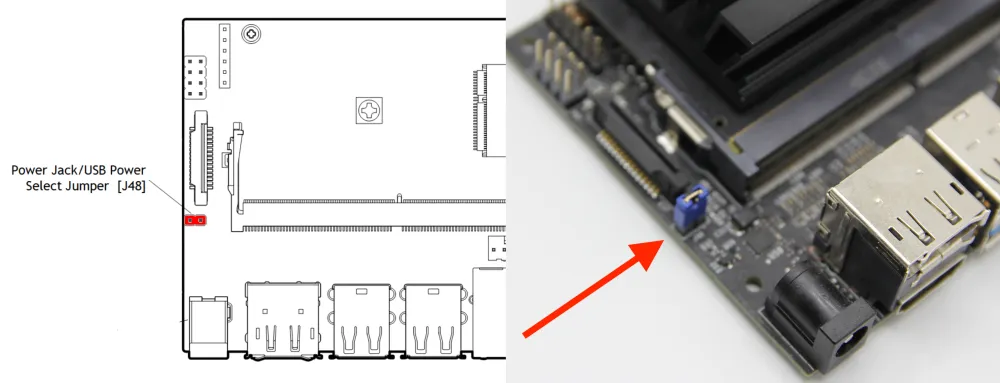
NX 也是左侧一个 DC 右侧一个 MicroUSB 但是 NX 的 DC 是 9-19V 5A MAX 宽输入,右侧 USB 仅限数据传输使用,不能用作供电
系统烧录
虽然官方文档推荐 microSD 卡大小,Nano 是 32G NX 是 16G, 但是官方 img 镜像的大小是 Nano 15G NX 17G,令人不禁怀疑是不是标反了。
Nano 的使用很简单,和树莓派一样,烧录 microSD,插电开机就能用了。NX 如果只使用 microSD 卡也是如此,但是 NX 下方有一条 nVME 槽,使用 SSD 显然比 tf 卡快速稳定许多。
但是如果想把系统安装在 ssd 中还需要一番折腾,jpack5.0 前需要 tf 卡安装系统后手动克隆到 ssd 并且是走 tf 卡启动后脚本挂载目录,非常原始。5.0 后可以通过 SDK manager 直接安装系统到 ssd,但是 SDK manager 有系统要求:Ubuntu 16.04, 18.04 and 20.04 on x86_64 system 或者 CentOS/RHEL 7.6, 8.0 and 8.2 on x86_64 system
而且因为走 SDK manager 安装是交叉编译 会需要大量时间 官方文档介绍需要一个半小时 实际因为网络情况可能得四五个小时起步
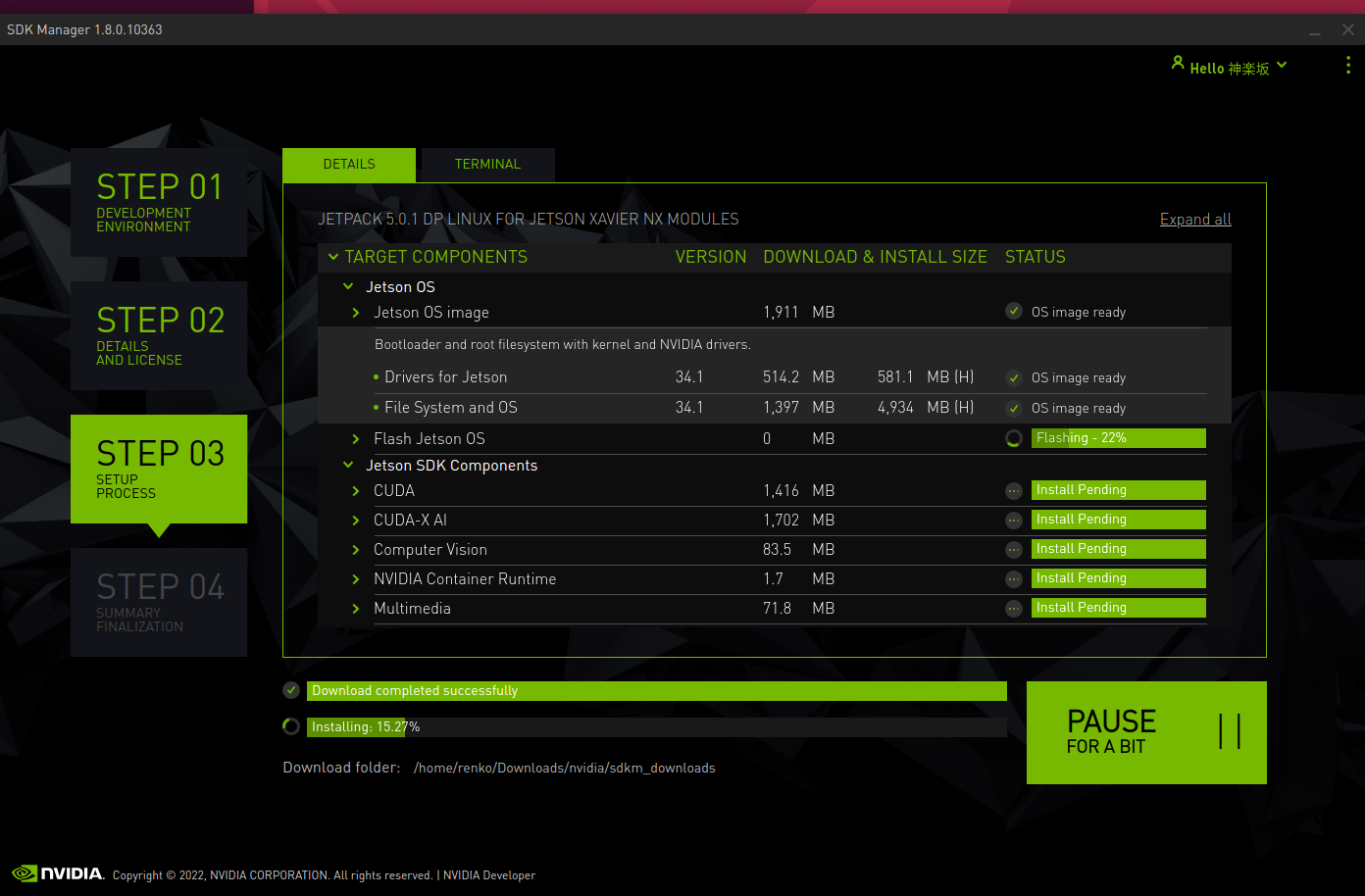
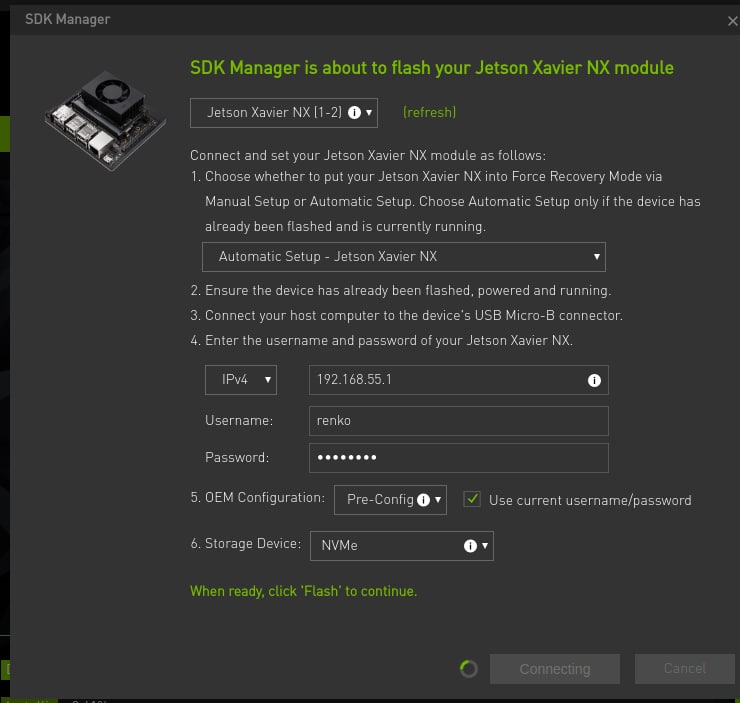
系统精简 & 调优
Nano 如果使用 16G microSD 卡,可以删除 gnome 使用自带的 lxde、libreoffice、本地 repo 节省 1G 内存和接近 2G 的 tf 卡空间
NX 同理 但是相比只有 4G 内存的 Nano 还是没有节省的必要(不过既然要作为 k3s 节点使用 反正桌面也用不上)
1 | # Step 1, remove office |
jtop 安装
Jtop 是一个实时查看和控制 NVIDIA Jetson 的状态的小工具,能非常方便地看到当前 Jetson 机器上的各种完整信息,一般在首页就可以读取到很丰富的数据信息
- ALL:
包含模块运行信息包括:CPU、内存、GPU、磁盘、风扇、jetson_clock 状态、NVPModel 等等 - GPU:
实时 GPU 状态 - CPU
实时 CPU 状态 - CTRL
可以控制的项目,如风扇和功率 - INFO
Lib 库、CUDA、Serial Number、Interface 等信息
1 | sudo apt-get install python3-pip -y |
Jetson 集群!之 准备工作
1 | echo "`id -nu` ALL=(ALL) NOPASSWD: ALL" | sudo tee /etc/sudoers.d/`id -nu` |
禁用 GUI 模式,默认是启用的,会消耗资源:
1 | sudo systemctl set-default multi-user.target |
记住,这样做,你的 Jetson 将启动到文本模式。但是,如果需要,您可以通过将默认系统模式重置为 “graphics.target” 来改回桌面环境。
确认你的 NANO 或 NX 是在最大性能模式下:
1 | sudo nvpmodel -m 0 |
这通常是一个默认设置。然而最好还是检查一下。低功耗 (5W) 模式降低了板的计算性能。
禁用 swap——swap 会导致 Kubernetes 的问题:
1 | sudo swapoff -a |
将 NVidia 运行时设置为 Docker 中的默认运行时。对于这个编辑 /etc/docker/daemon.json 文件,所以它看起来像这样:
1 | { |
Docker® 引擎使用的默认运行时是 runc 更改默认运行时为 nvidia-container-runtime 可以免去输入–runtime=nvidia
安装 Curl (默认居然没有!
1 | sudo apt install curl git |
Jetson 集群!之 k3s 安装
在 Master(本处为 NX)上安装 K3S Server:
执行指令如下:
1 | curl -sfL https://rancher-mirror.oss-cn-beijing.aliyuncs.com/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn INSTALL_K3S_EXEC="--docker" sh -s - |
^ Rancher 似乎对最新版的兼容性不太好 可以通过 INSTALL_K3S_VERSION 设置版本 如 INSTALL_K3S_VERSION=v1.23.6+k3s1
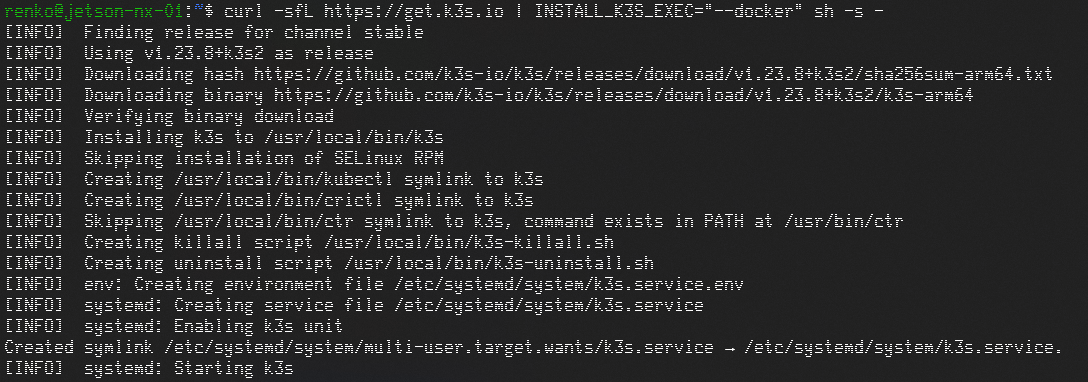
检测是否安装完成:
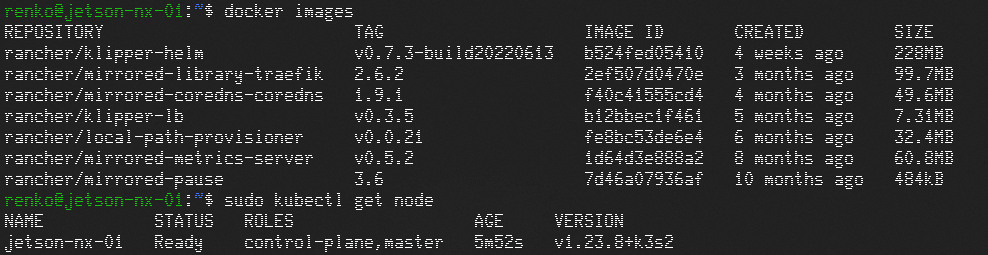
1 | docker images |
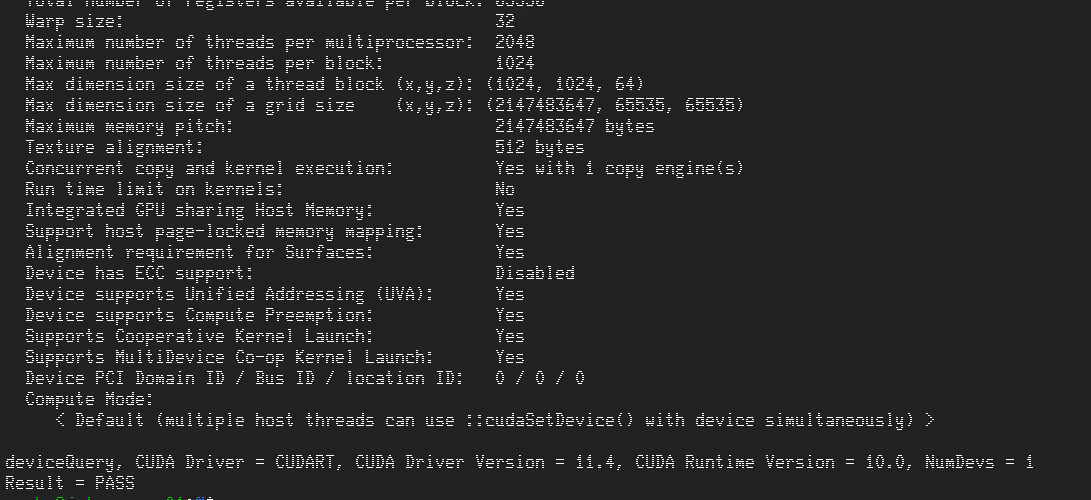
测试能否执行计算,执行一个第三方打包好的 cuda devicequery 容器:
1 | sudo kubectl run -it nvidia --image=jitteam/devicequery --restart=Never |
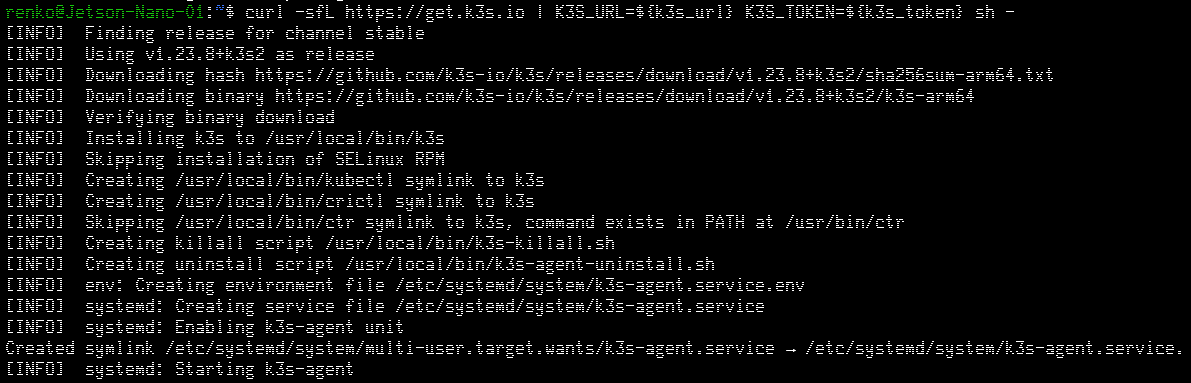
在三个 Worker 上(本处为 node1/node2/node3)上安装 K3S agent:
首先在 Master(这里是 node0)上找到 k3s Server 的密钥(token),执行以下指令
1 | sudo cat /var/lib/rancher/k3s/server/node-token |

在每个 worker(node1/node2/node3)上执行
1 | export k3s_token="<前一步显示的node-token字符串>" |
然后执行下面指令:
1 | curl -sfL https://rancher-mirror.oss-cn-beijing.aliyuncs.com/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn K3S_URL=${k3s_url} K3S_TOKEN=${k3s_token} INSTALL_K3S_EXEC="--docker" sh - |
在 Master 上执行下面指令,检测 agent 安装:
1 | sudo kubectl get nodes |

这就表示 worker 节点已经进入这个 k3s 管理范围内,只不过还没设定角色
为每个 worker 设定角色:在 Master 节点(node0)上执行角色设定指令
sudo kubectl label node node1 node2 node3 node-role.kubernetes.io/worker=worker

再检测一下节点状态:
sudo kubectl get nodes

在 Kubernetes 中启用 GPU 支持
在集群中的所有 GPU 节点上配置上述选项后,您可以通过部署以下守护程序集来启用 GPU 支持:
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.12.2/nvidia-device-plugin.yml
常规安装不适用于 Jetson,你需要经历一番折腾才可以在 Kubernetes 中启用 GPU 支持
其实你完全不需要这东西,只要你假定每个节点都能跑 CUDA,这东西就没有意义
如果你一定想要个 以下是食用方法:
要让 device-plugin 在 ARM64 架构上工作,我们需要使用以下补丁编辑 NVIDIA 设备插件:
0001-arm64-add-support-for-arm64-architectures.patch
0002-nvidia-Add-support-for-tegra-boards.patch
0003-main-Add-support-for-tegra-boards.patch
克隆原始 NVIDIA device-plugin 存储库并应用补丁:
1 | $ git clone -b 1.0.0-beta6 https://github.com/nvidia/k8s-device-plugin.git |
然后,构建 device-plugin 容器:
1 | $ docker build -t nvidia/k8s-device-plugin:1.0.0-beta6 -f docker/arm64/Dockerfile.ubuntu16.04 . |
接下来,将容器部署到您的集群中:
1 | $ kubectl apply -f nvidia-device-plugin.yml |
最后,检查 pod 的状态以及它们都运行之前的状态:
1 | $ kubectl get pods -A |
设备插件的示例输出如下:
1 | kubectl logs nvidia-device-plugin-daemonset-k8g57 --namespace=kube-system |